
Warning: this is a blogpost for the especially interested or very particular type of geek. It goes deep into the weeds, in order to suggest how civil society organizations should determine appropriate content for consent policies.
There are a number of thorny ethical issues that accompany data’s tremendous potential for civil society, and consent is among the thorniest. Developed in the context of medical research, the notion of informed consent suggests that when you study people, or collect data from them, those people should participate in that research voluntarily, ideally with a sound understanding of what the research is about and how the data they provide will be used.
This is tricky for researchers using new media tools to collect and process data, firstly because impersonal sources such as “big data” can be argued to obviate the need for consent, since there is no direct interaction with human subjects, and secondly because of how easily digital data can be aggregated, processed, re-used, re-appropriated and abused. The risks are far reaching and difficult to anticipate. These challenges have inspired a protracted debate in the traditional research community, but it’s even more pressing for civil society and advocacy.
 When civil society aims to collect and leverage data for social good, there may be explicit data collection from individuals, such as SMS reporting, web surveys and online petitions. Mapping of public service points like water pumps or community land claims, however, are less clear. But all data, with analysis and comparison, is human data and eventually reflects on people. And if civil society’s objective is social good, to improve the livelihoods or opportunities of people, then it’s easy to argue that securing their consent is critical if it helps to ensure that such efforts don’t do harm. (For some of our thinking on how this plays out in the humanitarian context, see this article [in Norwegian and google translated] and slide deck).
When civil society aims to collect and leverage data for social good, there may be explicit data collection from individuals, such as SMS reporting, web surveys and online petitions. Mapping of public service points like water pumps or community land claims, however, are less clear. But all data, with analysis and comparison, is human data and eventually reflects on people. And if civil society’s objective is social good, to improve the livelihoods or opportunities of people, then it’s easy to argue that securing their consent is critical if it helps to ensure that such efforts don’t do harm. (For some of our thinking on how this plays out in the humanitarian context, see this article [in Norwegian and google translated] and slide deck).
The trouble is that obtaining consent is hard. For organizations stretched thin and working in challenging contexts, conceptualizing consent can be even harder. Where to start?
Last week, Stanford PACS’s Digital Civil Society Lab hosted a conference on Ethics of Data for Civil Society, where we had the opportunity to throw some incredible brain power at this question. Daniel Gilman (UN OCHA), Janet Haven (Open Society Foundations), Kate Crawford (Microsoft Research / MIT Center for Civic Media), John Wilbanks (Sage Bionetworks), Sheila Warren (Tech Soup Global) and Tracy Ann Kosa (Microsoft) joined a conversation about what consent looks like for most civil society data projects, and what it should look like. This blogpost summarizes those discussions, and suggests a model that civil society organizations can use to develop appropriate consent policies.
3 types of consent
To start thinking about how to conceptualize and obtain consent, we first divided the broader issue of consent into three distinct types:
-
Informed consent, where data subjects (people whose data is collected or who are reflected in data) are informed about how that data will be used and consent knowingly to that data being used. We most often see this applied in academic research with human subjects or in the release of records, but rarely if at all in civil society initiatives.
-
Simple consent, where people consent to processes without much information about what it implies. This is most commonly manifest as a checkbox, and we see it in registration or membership clickthroughs and online services, as well as most citizen reporting initiatives on events or public services.
-
Coerced consent, where people consenting don’t really have a choice, either because there are few (or no) alternatives, or because they are compelled by circumstance to consent. For the research or private sectors, this is common in service improvement research; for civil society, it’s common in emergencies.
For each of these, we saw a number of components that would ideally be present in a consent policy to greater or lesser degree:
-
Review by some kind of expert or informed body
-
Time restriction (data can only be kept/used for a certain amount of time)
-
Use restriction (data can only be kept/used for specific purposes)
-
Transparency & explication (nature of data use must be explained and available to the public)
-
Enforcement of the consent policy and penalties in the case of breaches
-
Risk assessments to inform consent policies (this is arguably the most important component, as it will inform decisions on all the others)
Where’s the beef?
The next question we asked was how these different components might play out. There are a million different ways that expert review might be structured, and different models will be appropriate in different contexts. But what are some of the likely models? Can these represent best practices for expert review to improve civil society practice? Is there a basic minimum standard that should apply to all types of civil society consent policies? What is considered an appropriate sanction for a breach of consent? What are the logistical challenges to distinguishing between personal and aggregate data?
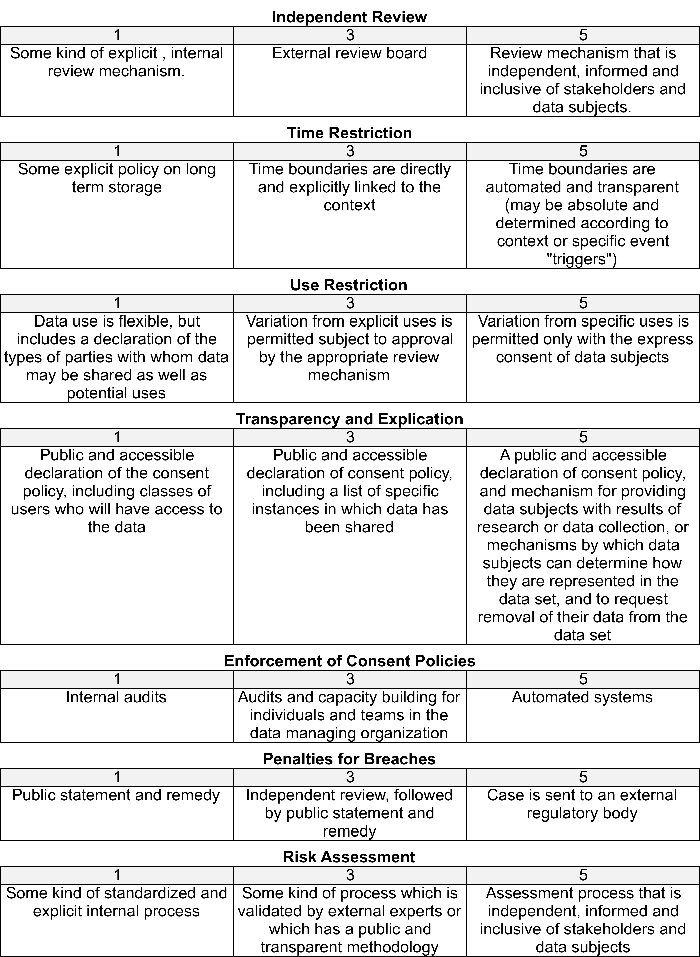 To try and answer some of these questions, we applied a 5 point scale to each of the components, so that they could be ranked according to a system in which 5 represented the most stringent and risk-sensitive position that a consent policy could adopt, and 1 represented the bare minimum that is ethically justifiable. To make these numbers meaningful, we suggested categories for each component at the rankings of 1, 3 and 5.
To try and answer some of these questions, we applied a 5 point scale to each of the components, so that they could be ranked according to a system in which 5 represented the most stringent and risk-sensitive position that a consent policy could adopt, and 1 represented the bare minimum that is ethically justifiable. To make these numbers meaningful, we suggested categories for each component at the rankings of 1, 3 and 5.
It’s worth reiterating that this is a normative exercise. This range represents one perspective on what civil society should be doing. The 1’s represent the bare minimum.
What’s most appropriate
Once we had mapped out the scope of appropriate positions for each of these components, we tried to place them within the three types of consent we had originally delineated (informed, simple and coerced). The number ranks represent the suggested rigor that a consent policy should have, depending on whether the type of consent is informed, simple or coerced (it doesn’t suggest how to determine which of these three types of consent is most appropriate).
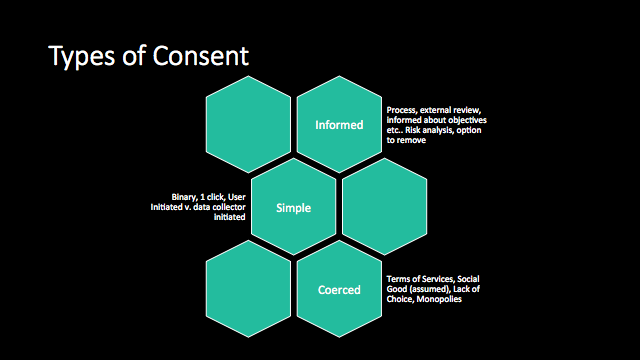
We could discuss, likely without end, whether this is or isn’t the most appropriate normative distribution. What is perhaps most interesting, however, is the implication that the less informed consent is, the more rigorous and progressive a consent policy needs to be. If data subjects aren’t enabled to make informed decisions about their participation in civil society data projects, then there need to be mature policies in place that include strict mechanisms to manage how data is used. This is most obvious in the coerced consent column, where a straight line of 5’s suggests that in situations like humanitarian response, where informed or even simple consent might not be an option, radical transparency, external review and stringent controls for how data is used and stored may be a must.
It’s also worth noting that we struggled with the timing of some of these components, especially in the coerced column. For example, full transparency might not be appropriate for humanitarian data collection during crisis, and risk assessments might not be feasible prior to data collection for emergency response. In cases like these, we concluded that mature approaches to consent components were absolute requirements at some point in time. This deserves closer consideration.
Lastly, it’s worth noting that we assigned a general progression of increasing maturity from left to right (stricter mechanisms as we move from informed towards coerced consent). The single exception to this regards risk assessments, which we asserted should never drop below a three. We felt this was especially true for informed consent, because this process is necessary to determine what data subjects need to be informed about.
What’s next?
This was a first pass at a terribly complicated issue that isn’t well explored. It was also a conversation in a small bubble in Stanford, so would likely benefit from review, not in the least by people from civil society who are thinking about consent. It does seem to be an important first stab at a framework, however, and we’re excited to see what can be made of it to help civil society projects make their own decisions about what’s the most appropriate policy and mechanisms for consent in their own contexts. We’ll be taking this forward at the Responsible Resource Sprint in Budapest at the end of this month, and the Nairobi Responsible Data Forum on consent and crowdsourcing at the end of October, to see if it can be operationalized. If you have comments, would like to join us, or would like to try and apply this in your work, let us know.
For a more concise presentation of what the working group produced, take a look at this Power Point presentation produced by Tracy Ann Kosa.
This blogpost was written from jumbled notes and memory. Inaccuracies and misrepresentations of the other participants in the Stanford working group may be present throughout, and any blind spots or faulty reasoning should be attributed to me alone.



Where is the option of bonus for consent?
In order to recertify for HUD last year, I had to “give consent” for them to have access to my financial data. This is intrusive as there is no way to block information about vendors that I am paying for product/services. That shouldn’t be any of their business. But since I’m doing nothing wrong, I don’t really have a problem as long as they aren’t selling that data to whomever will pay a hefty price or using it to build a file on me that can be manipulated and subpoenaed by a court in a case regarding some Thought Crime kind of thing. But instead of asking me nicely, or offering a carrot if I comply (such as a reduction in rent), they threaten to kick me out on the street if I don’t comply. This is not “consent”. This is coercion. I would die out there. There are plenty of reasons why people will resist coercion besides just being a criminal and hiding their criminal activity.
Why not set the rents an extra $20 (or whatever) higher to offset any costs for fraud to them and offer to keep it down to normal with an added 10% discount if I comply? They will have less turnover and therefor less paperwork. They will not lose any money either way. I will not lose my life and I will gain if I comply, but not at any real cost to them since the funds are already collected from those who don’t comply.
Where is this option?
And isn’t it ironic that this option is not mentioned on a page that is also sporting the logos of “Amnesty International” and other supposedly “Open” type organizations?